
목차
- 동적 계획법이란
- Top-Down와 Bottom-Up
- Coin Change Problem
- Knapsack
- Longest Common Subsequence
- Longest Increasing Subsequence
- Edit Distance
- Matrix Chain Multiplication
1. 동적계획법이란
흔히 DP라 불리는 동적 계획법이란, 복잡한 문제를 여러 개의 작은 부분 문제(sub-problem)로 나누어 해결하는 문제 해결 기법입니다. 동적 계획법의 특징 중 하나는 이미 계산된 부분 문제가 다시 발생하면 새롭게 계산하지 않고 이전의 계산값을 참조하여 이용하는 것입니다. 이 방법은 부분 문제를 다시 해결하는 데 필요한 시간을 절약할 수 있지만, 이전 계산값을 저장해 둘 공간이 필요하므로 시간과 메모리의 trade-off라고 할 수 있습니다.
동적 계획법이 사용되는 대표적인 예제로 분할정복에서 잠깐 살펴본 피보나치 함수의 계산이 있습니다. 피보나치 함수란 다음과 같이 정의됩니다.
fib(N) = fib(N - 1) + fib(N - 2) (fib(0) = 1, fib(1) = 1)
fib(7)을 단순 탐색으로 구현하려고 한다면 아래와 같은 sub-problem으로 나누어집니다.

위와 같이 fib(5)가 2번, fib(4)는 3번, fib(3)은 5번, fib(2)는 8번, fib(1)은 5번씩 호출됩니다. fib(N)에 대한 결과값은 언제나 일정하므로, 같은 파라미터를 가진 함수를 중복 호출은 굉장히 비효율적입니다. 이를 해결할 수 있는 것이 Memoization입니다.
Memoization이란 한 번 계산된 값을 기록해두고 이후 중복 호출되었을 때 새롭게 계산하는 것이 아닌 저장해 둔 값을 가져와 사용하는 방법입니다. 예를 들어 fib(N)이 호출되었을 때, fib_value[N]이 이미 계산되어 있는 값이라면 이를 그대로 돌려주고, 아니라면 fib(N-1)과 fib(N-2)을 호출하여 그 합을 fib_value[N]에 저장하는 것입니다. 이를 이용하면 아래와 같이 연산량이 줄어듭니다.

2. Top-Down와 Bottom-Up
동적 계획법의 구현은 크게 Top-Down방식과 Bottom-Up방식으로 나뉘어집니다. Top-Down방식은 큰 문제에서 작은 부분문제를 재귀적으로 호출하여 리턴되는 값을 이용하여 큰 문제를 해결하는 방식입니다. 중복되는 부분문제를 피하기 위해 앞서 소개한 Memoization기법을 함께 사용하며, 위에서 다룬 피보나치 함수의 구현방법 또한 이에 속합니다.
반대로 Bottom-Up방식은 작은 부분문제들을 미리 계산해두고, 이 부분문제들을 모아 큰 문제를 해결하는 방식입니다. 일반적으로 배열에 값을 채워나가는 형태로 구현합니다. 피보나치 함수를 Bottom-Up 방식으로 구현하면 아래와 같습니다.

두 가지 방법은 각각의 장단점이 있습니다. Top-Down방식의 경우, 재귀함수를 통해 구현되므로 함수 호출에 대한 오버헤드가 발생합니다. 반면 Bottom-Up방식의 경우 반복문을 통해 구현되므로 이러한 자원에 비교적 자유로워 시간 및 메모리의 최적화가 쉽습니다.
하지만 Bottom-Up방식의 경우 큰 문제를 해결하기까지 어떠한 sub-problem이 요구되는지 알 수 없으므로 전체 문제를 계산하기 위해 모든 부분문제를 해결해야 합니다. 하지만 Top-Down방식의 경우 큰 문제를 해결하기 위해 필요한 sub-problem만을 호출하므로 필요한 부분만 계산하게 되어 특정한 경우에는 Bottom-Up방식보다 빠르게 동작할 수 있습니다.
3. Coin Change Problem
동적계획법의 또 다른 대표적인 예로 Coin Change Problem(동전 교환 문제)이 있습니다. 동전 교환 문제란 동전의 종류 N과 각 동전의 금액이 주어졌을 때 특정 금액 K를 만들기 위한 동전의 최소 개수를 구하는 문제입니다. 이때 각 동전의 개수는 무한히 많다고 가정합시다.
1, 5, 12원짜리 동전이 있고, 15원을 만들어야 하는 경우를 생각해 봅시다. 이를 해결할 때 가장 먼저 떠오르는 것은 가장 큰 금액의 동전부터 먼저 사용하는 Greedy한 방법입니다. 동전을 적게 쓰기 위해서는 큰 동전을 쓰는 것이 유리하다는 생각으로 먼저 12원짜리 동전을, 이후 남은 3원을 1원짜리 동전 세 개로 채워 12 + 1 + 1 + 1의 총 4개의 동전으로 15원을 만듭니다. 하지만 이 경우는 최적값이 아닙니다. 5 + 5 + 5 총 3개의 동전으로 15원을 만드는 방법이 있기 때문입니다.
이를 해결하기 위해서는 어떻게 해야 할까요? 사용한 Greedy 방법을 계속 확장해봅시다. 다음 차례로는 12원짜리 동전을 하나 제외하고, 다음으로 큰 5원짜리 동전을 최대한 많이 사용하게 될 것입니다. 5 + 5 + 5라는 최적값을 찾게 됩니다. 하지만 만약 이보다 동전을 적게 사용하는 해가 있다면 어떻게 될까요? 또한 이 값이 최적값이라는 것을 어떻게 확신할 수 있을까요? 모릅니다. 결국 Greedy 방법은 모든 경우를 다 찾게 될 것입니다. 동전이 100개만 되더라도 그 경우의 수는 계산이 힘들 만큼 많아집니다.
이때 사용하게 되는 것이 동적계획법입니다. C[N] = {1, 5, 12}, D[i]: ‘i원을 만들기 위해 필요한 동전의 최소개수’라고 정의합시다. 우리는 D[K]에 대해 아래와 같은 점화식을 세울 수 있습니다.
D[K] = Mini=0 to N-1, K > C[i](D[K - C[i]]) + 1
위 식은 K원을 만들기 위해서는 K보다 작은 금액에 새로운 동전이 더해지는 원리입니다. 더해지는 새로운 동전의 금액이 C[i]라면 D[K](K원을 만들기 위해 필요한 동전의 최소개수)의 후보값은 N개의 금액에 대해서 D[K - C[i]]((K - C[i])원을 만들기 위해 필요한 동전의 최소개수)에 C[i]원 동전 하나를 추가하는 방법들이 될 것입니다. 이는 결국 D[K]라는 큰 문제를 D[K - C[i]]라는 sub-problem으로 나누어 풀게 되는 동적 계획법이 됩니다.
다음은 동전 교환 문제를 동적 계획법으로 푼 코드입니다.
| 입력 | 출력 |
| 첫 줄에 동전의 개수 N과 만들어야 하는 금액 K가 주어집니다. (1 ≤ N ≤ 100, 1 ≤ K ≤ 10,000) 둘째 줄에 N개의 동전의 금액이 주어집니다. 모든 동전의 금액은 10,000보다 작거나 같은 양의 정수입니다. |
K원을 만들기 위해 필요한 동전의 최소개수를 출력합니다. 만약 K원을 만드는게 불가능하다면 -1을 출력합니다. |
| Sample Input | Sample Output |
| 3 15 1 5 12 |
3 |
C++
#include <iostream>
using namespace std;
int coin[100], d[10001];
int main() {
int n, k;
cin >> n >> k;
for(int i = 0; i < n; i++) {
cin >> coin[i];
}
for(int i = 1; i <= k; i++) {
d[i] = -1;
for(int j = 0; j < n; j++) {
if(coin[j] <= i) {
if(d[i - coin[j]] < 0) continue;
if(d[i] < 0) d[i] = d[i - coin[j]] + 1;
else if(d[i - coin[j]] + 1 < d[i]) d[i] = d[i - coin[j]] + 1;
}
}
}
cout << d[k] << "\n";
return 0;
}Java
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int k = scanner.nextInt();
int coin[] = new int[n];
for (int i = 0; i < n; i++) {
coin[i] = scanner.nextInt();
}
int d[] = new int[k + 1];
for (int i = 1; i <= k; i++) {
d[i] = -1;
for (int j = 0; j < n; j++) {
if (coin[j] <= i) {
if (d[i - coin[j]] < 0) continue;
if (d[i] < 0) d[i] = d[i - coin[j]] + 1;
else if (d[i - coin[j]] + 1 < d[i]) d[i] = d[i - coin[j]] + 1;
}
}
}
System.out.println(d[k]);
}
}4. Knapsack Problem
다이나믹 프로그래밍이 사용되는 대표적인 예제에 Knapsack(배낭) 문제가 있습니다. 배낭 문제란, 무게 제한이 K인 배낭과 무게와 가치가 정해진 N개의 물건이 있을 때 가치의 총합이 가장 크도록 배낭을 싸는 문제입니다.
이때 각 물건은 하나씩만 존재하며 나누어 넣을 수 없습니다. 따라서 각 물건은 배낭에 넣거나, 넣지 않거나 둘 중 하나의 경우를 가집니다. 배낭에 넣은 물건 무게의 총합은 배낭의 무게 제한을 넘어서는 안 됩니다.
무게 제한이 7kg인 배낭과 아래와 같이 4개의 물건이 있을 때를 생각해봅시다. 각 물건에서 Vi는 그 물건의 가치를, Wi는 물건의 무게를 나타냅니다.
| i | V | W |
| 1 | 13 | 6 |
| 2 | 8 | 4 |
| 3 | 6 | 3 |
| 4 | 12 | 5 |
이때 가치의 총합이 가장 크도록 가방을 싸려면, 어떤 물건들을 넣어야 할까요?
동전 교환 문제와 마찬가지로 일반적으로 떠오르는 방법은 무게당 가치가 가장 높은 물건을 먼저 넣는 Greedy한 방법입니다. 무게당 가치를 계산해, 그 값이 높은 순으로 정렬한다면 위 표는 아래와 같아집니다.
| i | V | W | V[i]/W[i] |
| 4 | 12 | 5 | 2.40 |
| 1 | 13 | 6 | 2.17 |
| 2 | 8 | 4 | 2.00 |
| 3 | 6 | 3 | 2.00 |
가장 먼저 무게당 가치가 가장 높은 4번 물건을 가방에 넣습니다. 가방은 5kg이 차고 이때 가치의 합은 12입니다. 남은 무게 2kg에 대해 더 넣을 수 있는 물건이 없으므로 12가 최적값의 후보가 됩니다.
하지만 이는 최적값이 아닙니다. 이 문제의 최적값은 2번 물건과 3번 물건을 넣어 7kg으로 가방을 채운 가치의 합 14입니다.
역시 최적값을 찾기 위해 Greedy 방법을 계속 확장해봅시다. 다음 차례로는 4번 아이템을 빼고 그다음으로 무게당 가치가 높은 1번 물건을 가방에 넣습니다.
이때 가방은 6kg이 차고 가치의 합은 13이 됩니다. 남은 무게 1kg에 대해 더 넣을 수 있는 물건이 없으므로 13이 최적값의 후보가 됩니다. 다음으로 역시 1번 물건을 빼고 2번 물건을 넣습니다.
이때 가방은 4kg에 8의 가치합을 갖습니다. 남은 무게 3kg에 대해 3번 아이템을 추가로 넣을 수 있으므로 우리는 7kg에 14라는 최적값에 도달하게 됩니다.
하지만 이 값이 최적값이라는 것을 확신할 수 있을까요? 이보다 물건이 훨씬 다양해지고 가방의 중량 제한이 커진다면 어떻게 될까요? 우리는 이러한 Greedy한 방법으로는 구한 값이 최적인지 확신할 수 없습니다.
따라서 결국 모든 경우의 수를 다 보게 될 것입니다. 앞서 다룬 동전 문제와 같은 문제점에 도달하게 됩니다.
역시 해결 방법은 동적계획법입니다. V[N] = {13, 8, 6, 12}, W[N] = {6, 4, 3, 5}, D[i][j]: 'i번째 물건까지 넣는다/안 넣는다를 정했을 때, 무게 j이하를 채우는 가치의 합 중 최대값'이라고 정의합시다. 우리는 D[i][j]에 대해 아래와 같은 점화식을 세울 수 있습니다.
D[i][j] = Max(D[i-1][j], D[i-1][j - W[i]] + V[i])
위 D[i][j]를 채우는 두 가지 경우를 점화식으로 나타낸 것으로, D[i-1][j]는 i번째 물건을 넣지 않는 상태를, D[i-1][j-W[i]] + V[i]는 i번째 물건을 넣는 상태를 의미합니다.
이는 결국 D[N][K]라는 큰 문제를 위와 같은 형태의 sub-problem으로 나누어 풀게 되는 동적 계획법이 됩니다.
다음은 배낭 문제를 동적 계획법으로 푼 코드입니다.
| 입력 | 출력 |
| 첫 줄에 물건의 개수 N과 배낭의 무게 제한 K가 주어집니다. (1 ≤ N ≤ 100, 1 ≤ K ≤ 10,000) 둘째 줄부터 N개의 줄에 걸쳐 각 물건의 가치 Vi와 무게 Wi가 주어집니다. (1 ≤ Vi, Wi ≤ 10,000) |
무게 제한 K안에서 담을 수 있는 물건 가치 총합의 최대값을 출력합니다. |
| Sample Input | Sample Output |
| 4 7 13 6 8 4 6 3 12 5 |
14 |
C++
#include <iostream>
using namespace std;
int d[101][10001], v[101], w[101];
int main() {
int n, k;
cin >> n >> k;
for(int i = 1; i <= n; i++) {
cin >> v[i] >> w[i];
}
for(int i = 1; i <= n; i++) {
for(int j = 0; j <= k; j++) {
if(j < w[i]) {
d[i][j] = d[i - 1][j];
} else if(d[i - 1][j - w[i]] + v[i] > d[i - 1][j]) {
d[i][j] = d[i - 1][j - w[i]] + v[i];
} else {
d[i][j] = d[i - 1][j];
}
}
}
int ans = 0;
for(int i = 0; i <= k; i++){
if(ans < d[n][i]){
ans = d[n][i];
}
}
cout << ans << "\n";
return 0;
}Java
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int k = sc.nextInt();
int v[] = new int[n + 1];
int w[] = new int[n + 1];
for (int i = 1; i <= n; i++) {
v[i] = sc.nextInt();
w[i] = sc.nextInt();
}
int d[][] = new int[n + 1][k + 1];
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= k; j++) {
if (j < w[i]) {
d[i][j] = d[i - 1][j];
}
else if (d[i - 1][j - w[i]] + v[i] > d[i - 1][j]) {
d[i][j] = d[i - 1][j - w[i]] + v[i];
}
else {
d[i][j] = d[i - 1][j];
}
}
}
int ans = 0;
for(int i = 0; i <= k; i++){
if(ans < d[n][i]){
ans = d[n][i];
}
}
System.out.println(ans);
}
}5. LCS (Longest Common Subsequence)
수열(sequence)의 부분 수열(subsequence)이란 기존 수열의 일부 항을 원래 순서대로 나열해 얻을 수 있는 모든 수열을 의미합니다.
최장 공통 부분수열(Longest Common Subsequence, LCS)이란 주어진 수열 모두의 부분 수열이 되는 수열 중 가장 긴 수열을 찾는 문제입니다. 예를 들어 아래와 같은 두 수열 A, B를 생각해 봅시다.
A = {1, 2, 3, 4, 5, 6}
B = {1, 3, 5, 4, 2, 6}
위 두 수열의 최장 공통 부분수열은 LCS(A, B)는 {1, 3, 4, 6} 또는 {1, 3, 5, 6}이며 그 길이는 4 입니다.
또한 LCS는 수열뿐만 아니라 순서를 가지는 모든 구조에 대해 적용할 수 있습니다. LCS를 문자열에 대해 적용해봅시다. "abaabcd"라는 문자열 A와 "baadca"라는 문자열 B가 있을 때, 두 문자열의 최장 공통 부분 수열 LCS(A, B)는 "baad" 또는 "baac"이며, 그 길이는 4가 됩니다.
이러한 LCS의 길이를 어떻게 구할 수 있을까요? 위에서 다룬 두 문자열을 통해 이를 알아봅시다.

A문자열의 길이를 LA, B문자열의 길이를 LB라고 할 때, 위와 같이 lcs[LA][LB] 테이블을 생각해봅시다.
이때 lcs[i][j]가 의미하는 것은 A문자열의 0~i번 인덱스까지의 부분 문자열(substring) A[0, i]와 B문자열의 0~j번 인덱스까지의 부분 문자열 B[0, j]의 LCS의 길이입니다. 즉 lcs 테이블은 아래와 같이 정의됩니다.
lcs[i][j] = LCS(A[0, i], B[0, j])의 길이
이제 lcs[i][j]를 살펴봅시다. 이 값은 다음과 같은 세 가지 상태로 나누어집니다.
1. lcs[i-1][j]에 A[i]가 새롭게 붙여진 경우
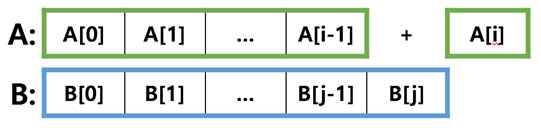
이미 구해진 lcs[i-1][j]에서 A[i]라는 글자가 하나 추가되어도 lcs[i][j]의 값은 증가할 수 없습니다.
B[j]까지는 이미 lcs[i-1][j]에서 사용되었을 수 있으므로 A[i]와 공통으로 사용될 B의 문자가 존재하지 않기 때문입니다. 따라서 이때 lcs[i][j]는 lcs[i-1][j]와 같은 값을 가질 수 있습니다.
2. lcs[i][j-1]에 B[j]가 새롭게 붙여진 경우

마찬가지로 lcs[i][j-1]에서 B[j]라는 글자가 하나 추가되어도 lcs[i][j]의 값은 증가할 수 없습니다.
A[i]까지는 이미 lcs[i][j-1]에서 사용되었을 수 있으므로 B[j]와 공통으로 사용될 A의 문자가 존재하지 않기 때문입니다. 따라서 이때 lcs[i][j]는 lcs[i][j-1]과 같은 값을 가질 수 있습니다.
3. lcs[i-1][j-1]에 A[i], B[j]가 새롭게 붙여진 경우

반면 lcs[i-1][j-1]에 A[i], B[j]라는 글자가 동시에 추가될 때를 생각해 봅시다.
만약 A[i]와 B[j]가 같은 글자라면 우리는 lcs[i][j]가 lcs[i-1][j-1]까지의 값에서 1 증가한다는 것을 알 수 있습니다. LCS(A[0, i-1], B[0, j-1]) 수열의 마지막에 A[i](B[j])가 추가되기 때문입니다.
이 세 가지 상태를 일반화하여 lcs의 점화식을 정리해보면 다음과 같습니다.

단 위 점화식의 경우 i가 0이거나 j가 0인 경우를 따로 처리해야만 합니다. 해당 점화식은 다음과 같습니다.
if(i == 0 && j == 0) lcs[i][j] = 1 (if A[i] == B[j])
else if(i == 0) lcs[i][j] = max(lcs[i][j-1], A[i] == B[j])
else if(j == 0) lcs[i][j] = max(lcs[i-1][j], A[i] == B[j])
이렇게 점화식의 경우가 다양해지는 불상사를 막기 위해, 문자열의 인덱스를 0이 아닌 1부터 시작하는 방법을 사용해볼 수 있습니다.
A의 인덱스가 [0, LA-1]이 아닌 [1, LA], B의 인덱스가 [0, LB-1]이 아닌 [1, LB]로 변경되면 점화식은 아래와 같이 한 번에 정리될 수 있습니다.

이 규칙에 따라 위에서 소개한 테이블을 각 문자열의 인덱스를 1부터 시작해 채워보면 아래와 같습니다.

이때 우리가 원하는 정답 LCS(A, B)의 길이는 테이블의 의미에 따라 lcs[LA][LB](LCA(A[1, LA], B[1, LB])의 길이)에 있는 4 가 됩니다.
다음은 두 문자열의 LCS의 길이를 동적 계획법으로 푼 코드입니다.
| 입력 | 출력 |
| 첫 줄에 문자열 A의 길이 LA와 문자열 B의 길이 LB가 주어집니다. (1 ≤ LA, LB ≤ 1,000) 둘째 줄에 문자열 A, 셋째 줄에 문자열 B가 주어집니다. |
두 문자열의 LCS의 길이를 출력합니다. |
| Sample Input | Sample Output |
| 7 6 abaabcd baadca |
4 |
C++
#include <iostream>
#include <string>
using namespace std;
int lcs[1001][1001];
string a, b;
int main() {
int la, lb;
cin >> la >> lb;
cin >> a >> b;
for(int i = 1; i <= la; i++) {
for(int j = 1; j <= lb; j++) {
if(a[i - 1] == b[j - 1]) {
lcs[i][j] = lcs[i - 1][j - 1] + 1;
} else {
if(lcs[i - 1][j] < lcs[i][j - 1]) {
lcs[i][j] = lcs[i][j - 1];
} else {
lcs[i][j] = lcs[i - 1][j];
}
}
}
}
cout << lcs[la][lb] << "\n";
return 0;
}Java
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int la = sc.nextInt();
int lb = sc.nextInt();
String a = sc.next();
String b = sc.next();
int lcs[][] = new int[la + 1][lb + 1];
for (int i = 1; i <= la; i++) {
for (int j = 1; j <= lb; j++) {
if (a.charAt(i - 1) == b.charAt(j - 1)) {
lcs[i][j] = lcs[i - 1][j - 1] + 1;
}
else {
if (lcs[i - 1][j] < lcs[i][j - 1]) {
lcs[i][j] = lcs[i][j - 1];
}
else {
lcs[i][j] = lcs[i - 1][j];
}
}
}
}
System.out.println(lcs[la][lb]);
}
}6. LIS (Longest Incresing Subsequence)
증가 수열(Increasing Sequence)란 수열 A의 임의의 원소 A[i], A[j](i < j)에 대해 A[i] < A[j]가 성립하는 수열입니다. 최장 증가 부분 수열(Longest Increasing Subsequence)이란 수열 A의 부분 수열 중 증가 수열이 되는 가장 긴 수열을 의미합니다. 예를 들어 아래와 같은 수열 A가 있을 때 LIS(A)를 구하면 다음과 같습니다.
A = {20, 1, 7, 4, 5, 6, 13, 3}
LIS(A) = {1, 4, 5, 6, 13}
우리의 목표는 이러한 LIS의 길이를 구하는 것입니다. 위 수열 A에서 LIS(A)의 길이는 5가 됩니다.
이 문제를 해결하기 위해, 다음과 D[i]를 'i번째 원소를 마지막으로 갖는 최장 증가 수열의 길이'라고 정의해봅시다.
그렇다면 임의 값 i에 대해 D[i]는 어떻게 구할 수 있을까요? 먼저 i번째 원소 A[i]가 수열의 마지막에 위치해야 한다는 특성을 생각해봅시다.
이는 A[i]이전의 원소들로 이루어진 수열에 A[i]를 마지막으로 추가한다는 의미가 됩니다. 또한 A[i]가 마지막 원소이면서, 증가 수열이기 위해서는 어떻게 해야 할까요?
A[i] 이전의 원소가 A[i]보다 작은 값을 가져야 합니다.
위 두 가지 특성을 정리해보면, D[i]의 값은 i보다 작은 j에 대해 A[j] < A[i]를 만족하는 D[j] 중 최댓값 + 1이 됩니다. 이를 점화식을 정리해보면 다음과 같습니다.
D[i] = Minj = 0 to i-1, A[j] < A[i](D[j]) + 1
위 식에 따라 예제 수열 A의 D테이블을 채워보겠습니다. 먼저 초기 상태는 아래와 같습니다.
| idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| A[i] | 20 | 1 | 7 | 4 | 5 | 6 | 13 | 3 |
| D[j] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
각 인덱스 i에 대해 우리는 A[j](0 ≤ j < i)가 마지막에 위치하며 길이가 D[j]인 증가 수열에 A[i]를 추가할 수 있는지 확인해야 합니다. 위에서 다뤘듯 '추가할 수 있다'의 기준은 A[i]가 A[j]보다 큰 것을 의미합니다.
0 ~ i-1까지 이를 만족하는 j중 가장 큰 D[j]를 D[i]에 저장합니다. 만약 해당하는 j가 없다면 D[i]는 0이 됩니다. 이후 D[i]에 1을 더합니다. 이 과정은 A[i]를 마지막 원소로 추가하여 길이가 1 증가하는 것을 의미합니다.
이를 통해 위 테이블을 갱신해나가면 결과는 아래와 같습니다.
| idx | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| A[i] | 20 | 1 | 7 | 4 | 5 | 6 | 13 | 3 |
| D[j] | 1 | 1 | 2 | 2 | 3 | 4 | 5 | 2 |
위 테이블에서도 확인할 수 있듯, D[i]의 결과는 뒤로 갈수록 커지는 형태가 아닙니다. A[i]의 값에 따라 D[i - 1]보다 D[i]가 작을 수도 있습니다. 따라서 최장 증가 부분 수열의 길이를 구하기 위해서는 D[i]의 값 중 가장 큰 값을 찾아야 합니다.
다음은 주어진 수열의 LIS의 길이를 구하는 코드입니다.
| 입력 | 출력 |
| 첫 줄에 원소의 개수 N이 주어집니다. (1 ≤ N ≤ 1,000) 둘째 줄에 각 원소의 값을 나타내는 정수 N개가 주어집니다. |
주어진 수열의 LIS 길이를 출력합니다. |
| Sample Input | Sample Output |
| 8 20 1 7 4 5 6 13 3 |
5 |
Java
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int a[] = new int[n];
for (int i = 0; i < n; i++) {
a[i] = sc.nextInt();
}
int d[] = new int[n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < i; j++) {
if (a[j] < a[i]) {
if (d[i] < d[j]) {
d[i] = d[j];
}
}
}
d[i]++;
}
int ans = 0;
for (int i = 0; i < n; i++) {
if (ans < d[i]) {
ans = d[i];
}
}
System.out.println(ans);
}
}7. Edit Distance
편집 거리(Edit Distance)는 문자열 A에서 문자열 B로 변경하는데 필요한 최소 연산 횟수를 구하는 문자열 유사도 판단 알고리즘입니다. 문자열 A에 대해 가능한 연산으로는 원하는 문자의 삽입, 삭제, 수정 등이 있습니다.
두 문자열 A: "kitten", B: "sitting"를 예로 들어봅시다.
우리는 A에 한 글자씩 삽입/삭제/수정하는 연산을 통해 B로 만들어야 합니다.
편의를 위해 문자열의 인덱스가 1부터 시작하도록 설정한 뒤, D[i][j]: A[1, i]까지 사용하여 B[1, j]까지 만들 때 필요한 최소 편집거리라고 정의한 다음과 같은 테이블을 생각해봅시다.

이 문제를 해결하기 위해서는 두 문자열에 대해서 한 문자씩 비교해 나가며, 각 위치별로 삽입/삭제/수정 연산의 경우를 다 따져봐야 합니다. LCS와 유사하게 D[i][j]는 다음과 같은 세 가지 상태로 나누어집니다.
- D[i - 1][j]에서 A[i]를 변형할 때 A[1, i - 1]은 B[1, j]와 동일하게 변형되어 있습니다. 따라서 A[i]는 삭제되어야 합니다.
- D[i][j - 1]에서 B[j]를 변형할 때 A[1, i]는 B[1, j - 1]과 동일하게 변형되어 있습니다. 여기에 B가 한 글자 증가하게 되면, A의 뒤에 B[j]를 삽입해야 합니다.
- D[i - 1][j - 1]에서 A[i]와 B[j]를 변형할 때 A[i]와 B[j]의 값이 같다면 A를 추가적으로 변형할 필요가 없습니다. 대신 A[i]와 B[j]가 다르다면 A[i]를 B[j]로 수정하는 연산이 필요합니다.
위 연산을 점화식으로 정리하면 아래와 같습니다.

위 점화식에 따라 테이블을 채우면 아래와 같습니다.
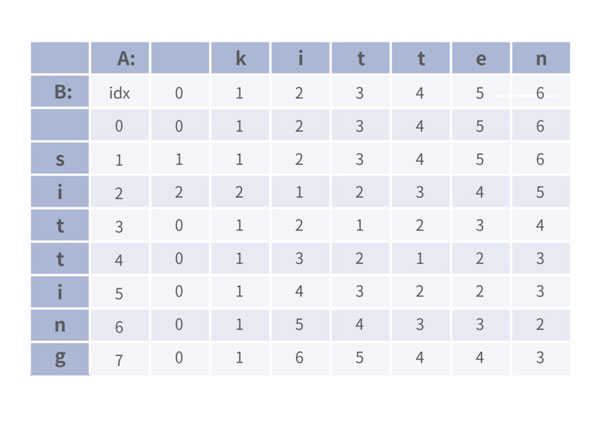
우리가 원하는 것은 A[1, LA]를 B[1, LB]로 변형시키는 것으로, 이 값은 테이블의 의미에 따라 D[LA][LB]에 들어있는 3이 됩니다. 다음과 같이 변형 과정을 거치면 3번 만에 "kitten"을 "sitting"으로 바꿀 수 있습니다.

다음은 두 문자열이 주어졌을 때 A를 B로 바꾸기 위한 최소 편집거리를 동적계획법으로 구현한 코드입니다.
| 입력 | 출력 |
| 첫 줄에 문자열 A의 길이 LA와 문자열 B의 길이 LB가 주어집니다. (1 ≤ LA, LB ≤ 1,000) 둘째 줄에 문자열 A, 셋째 줄에 문자열 B가 주어집니다. |
A를 B로 바꾸기 위한 최소 편집거리를 출력합니다. |
| Sample Input | Sample Output |
| 6 7 kitten sitting |
3 |
Java
import java.util.*;
import java.lang.*;
public class Main {
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int la = sc.nextInt();
int lb = sc.nextInt();
String a = sc.next();
String b = sc.next();
int d[][] = new int[la + 1][lb + 1];
for (int i = 1; i <= la; i++) {
d[i][0] = i;
}
for (int j = 1; j <= lb; j++) {
d[0][j] = j;
}
for (int i = 1; i <= la; i++) {
for (int j = 1; j <= lb; j++) {
if (a.charAt(i - 1) == b.charAt(j - 1)) {
d[i][j] = d[i - 1][j - 1];
}
else {
d[i][j] = Math.min(Math.min(d[i - 1][j], d[i][j - 1]), d[i - 1][j - 1]) + 1;
}
}
}
System.out.println(d[la][lb]);
}
}8. Matrix Chain Multiplication
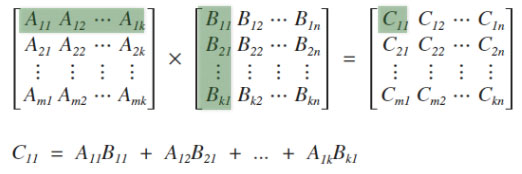
행렬의 곱셈에 대해 생각해봅시다.
N*M행렬 A와 M*K행렬 B가 있을 때, A * B의 결과 행렬 C의 크기는 N*K이며, C를 구하기 위해서는 N*M*K번의 곱셈이 수행됩니다.
이러한 성질 때문에 여러 행렬을 곱할 때, 어떠한 행렬쌍을 먼저 곱하는지에 따라서 전체의 곱셈 연산 횟수가 달라지게 됩니다.
Matrix Chain Multiplication은 이러한 곱셈 연산의 횟수를 최소로 하는 문제입니다.
A : 2*3 행렬, B : 3*5 행렬, C : 5*2 행렬
위와 같은 세 개의 행렬에 대해, A*B*C를 계산해야 한다고 생각해봅시다.
A*B*C를 연산하는 방법에는 아래와 같이 두 가지 경우가 있으며, 연산 순서에 따라 전체 연산 횟수가 달라짐을 알 수 있습니다.
- (A*B)*C
위 순서로 계산하는 경우 곱셈 연산의 횟수는 (2*3*5) + (2*5*2)로, 총 50번의 곱셈이 수행됩니다. - A*(B*C)
위 순서로 계산하는 경우 곱셈 연산의 횟수는 (3*5*2) + (2*3*2)로, 총 42번의 곱셈이 수행됩니다.
여러 개의 행렬을 곱해야 할 때 최소 곱셈 횟수를 구하는 문제에 대해서 생각해봅시다.
이 문제를 해결하기 위해서는 아래와 같은 테이블을 정의할 수 있습니다.
D[i][j] : i~j번까지의 행렬을 모두 곱하는데 드는 최소 곱셈횟수 (항상 i <= j를 만족한다.)
matrix[i][0] : i번째 행렬의 행의 수, matrix[i][1] : i번째 행렬의 열의 수
연속된 작은 구간들부터 연산해봅시다.
[i, j] 구간의 연속된 L개 행렬의 곱셈 연산을 생각해봅시다.
해당 구간의 L개 행렬 연산은 아래와 같이 나눠볼 수 있습니다.
- [i, i]의 결과 행렬 * [i + 1, j]의 결과 행렬
- [i, i + 1]의 결과 행렬 * [i + 2, j]의 결과 행렬
L-1. [i, j - 1]의 결과 행렬 * [j, j]의 결과 행렬
즉 [i, j]구간은 2개의 구간 [i, k], [k+1, j]로 나누어 2개의 결과 행렬을 곱하는 과정을 통해 구해질 수 있습니다.
이때 L개의 연속된 구간의 곱할 때 연산 횟수를 구하기 위해서는 위의 L-1가지 경우에서 쓰일 1 ~ L-1개의 연속된 구간의 곱할 때 최소 연산 횟수들이 필요합니다.
또한 [i, k]의 구간의 결과 행렬은 Ri * Ck의 크기를 가지며, [k+1, j] 구간의 결과 행렬은 Rk+1 * Cj의 크기를 가집니다.
따라서 두 구간의 연산 결과는 두 구간을 구하는데 필요했던 연산 횟수 + (Ri * Ck * Cj)가 됩니다.
이러한 특성을 정리하면 아래와 같은 점화식을 얻을 수 있습니다.
D[i][j]=0 (if i == j)
D[i][j] = Mink = i to j-1(D[i][k] + D[k+1][j] + (Ri * Ck * Cj)) if(i != j)
이때, 위에서 언급했듯 D[i][j]는 항상 구간 길이가 L보다 작은 구간만 참조하게 되므로, 구간의 길이가 짧은 테이블부터 채워 나가게 되면 D[0][N-1]에 전체 행렬을 곱하는데 필요한 최소 연산 횟수가 구해지게 됩니다.
다음은 곱해야 하는 행렬이 순서대로 주어졌을 때, 결과 행렬을 구하기 위해 필요한 최소 곱셈 횟수를 동적 계획법으로 구현한 코드입니다.
| 입력 | 출력 |
| 첫 줄에 행렬의 개수 N이 주어집니다. (1 ≤ N ≤ 500) 두번째 줄부터 N개의 줄에 각각의 행렬의 크기 R과 C가 주어집니다. (1 ≤ R, C ≤ 500) 이때 i번째 행렬의 R과 i+1번째 행렬의 C는 항상 같음이 보장됩니다. |
주어진 행렬 곱셈의 결과를 얻기 위해 필요한 최소 곱셈 횟수를 출력합니다. |
| Sample Input | Sample Output |
| 3 2 3 3 5 5 2 |
42 |
Java
import java.util.*;
public class Main {
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int r[] = new int[n];
int c[] = new int[n];
for (int i = 0; i < n; i++) {
r[i] = sc.nextInt();
c[i] = sc.nextInt();
}
int d[][] = new int[n][n];
for (int l = 1; l < n; l++) {
for (int i = 0; i < n - l; i++) {
int j = i + l;
d[i][j] = -1;
for (int k = i; k < j; k++) {
int calc = d[i][k] + d[k + 1][j] + r[i] * c[k] * c[j];
if (d[i][j] < 0) {
d[i][j] = calc;
}
else if (calc < d[i][j]) {
d[i][j] = calc;
}
}
}
}
System.out.println(d[0][n - 1]);
}
}