
1. Network Flow란
유량 그래프란 간선의 가중치가 정점에서 정점으로 보낼 수 있는 최대 유량을 의미하는 그래프입니다. 최대 유량이란 해당 간선을 통해 동시에 흘려보낼 수 있는 물의 최대치입니다. 이러한 유량 그래프에서 Source로 정의된 정점에서 Sink로 정의된 정점까지 최대 얼마만큼의 유량이 지나갈 수 있는지에 관한 문제를 Network Flow 혹은 Maximum Flow라고 정의합니다. 아래는 유량 그래프의 예시입니다.

각 간선을 유한 번 사용할 수 있는 통로라고 생각하고, 한 사람이 통로를 지나가면 사용할 수 있는 횟수가 한 번 줄어드는 문제를 생각해봅시다. 이때 무한히 많은 사람들이 Source에서 출발할 때, 최종적으로 Sink에 도달할 수 있는 사람의 수는 최대 몇 명일까요? 사람을 이동시키는 과정이 물을 흘리는 과정에 대입해보면 이러한 문제 역시 Network Flow문제로 정의할 수 있습니다.

위의 그림에서 Ci를 각 수로(간선)을 1초에 지날 수 있는 물의 최대치라고 정의합시다. 물이 각 수로에 흘러들어올 때 각 수로는 자신의 수용량 ci이상의 물은 통과시킬 수 없습니다. 따라서 전체 수로를 통과할 수 있는 물의 양은 2가 됩니다.
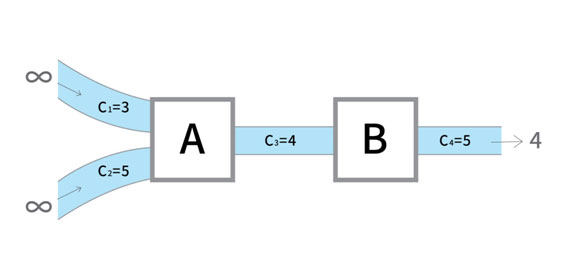
위의 그림에서 Ci가 각 통로를 사용할 수 있는 사람의 수라고 정의해봅시다. 수로의 개념을 적용해보면, 이때 수로를 완전히 빠져나올 수 있는 사람의 수는 최대 4명인 것을 알 수 있습니다. 1번 통로와 2번 통로를 통해서 A지점에 8명이 도착하더라도 결국 3번 통로를 사용할 수 있는 사람은 4명뿐이기 때문입니다.
이를 처음 주어진 유량 그래프에서 나타내보면 아래와 같이 결과를 표현할 수 있습니다.

위 그림에서 초록색 값은 각 간선의 최대유량(Capacity)이며, 붉은색 값은 실제로 해당 간선에 흐른 유량(flow)입니다. 위 그래프에서 source에서 sink로 보낼 수 있는 최대 유량(Maximum Flow)은 7이 됩니다.
2. Ford-Fulkerson Algorithm
그렇다면 이러한 Maximum-Flow를 어떻게 계산할 수 있을까요? Ford-Fulkerson Algorithm은 탐색을 통해 Source에서 Sink로 유량이 흐를 수 있는 경로를 탐색해 유량을 흘려보내는 알고리즘입니다.
Network Flow를 이해하기 위해서는 잔여 간선(Residual Edge)를 알아야 합니다. Residual Edge는 플로우가 흐르는 간선의 반대 방향으로 대칭적으로 존재하며, 잔여 간선의 가중치는 기준이 되는 기존 간선에 흐르는 플로우의 양과 같습니다. 예를 들어, 아래 그림에서 노드 A에서 노드B로 가는 간선의 Capacity가 7이고 현재 5의 플로우가 흐르고 있다면 잔여 간선은 반대 방향으로 5의 가중치를 가지고 존재합니다.

이러한 잔여 간선이 왜 필요할까요? 아래의 예시를 봅시다.

위와 같은 유량 그래프에 대해서 아래와 같은 상황을 가정해봅시다.

탐색을 통해 [A]와 같이 경로를 선택하게 된 경우, 우리는 총 7의 유량을 얻을 수 있습니다. 하지만 [B]의 경우처럼 이를 잘 분배하면 최대 9의 유량을 흘릴 수 있습니다.
왜 이런 차이가 발생할까요? 이유는 한 번 흘린 유량의 방향을 바꿀 수 없기 때문입니다. 따라서 [A]를 [B]와 같이 개선하기 위해서는 흘린 유량의 방향을 바꿀 수 있는 방법이 필요합니다. 예를 들어 [A]의 경우에서 B->E로 흘리는 유량을 4줄이는 대신 그 중 2만큼을 B->C로 우회시켜 A->D->E로 가는 유량을 4 증가시키면 [B]의 상황을 만들 수 있습니다. 이는 다시 해석하면 A->D->E로 흐르는 유량을 증가시키기 위해 기존에 B에서 E로 흘러들어오던 유량을 줄이고, 그 유량을 B가 E가 아닌 다른 노드로 흘려줄 수 있도록 우회경로를 찾아준 것과 같습니다.
이러한 우회경로를 찾을 수 있게하는 것이 바로 잔여 간선입니다. 잔여 간선이란 위에서 설명했듯 현재 흐르고 있는 플로우의 역으로 향하는 간선으로, 이 간선을 사용한다는 것은 이미 흘려준 플로우를 줄이고 다른 경로로 흘려주는 것과 같습니다. 즉 위의 잔여 간선 예제에서 잔여 간선은 “현재 A->B로 5의 유량이 흐르고 있으므로 경우에 따라 B에 들어오는 유량을 최대 5까지 줄여 A에서 다른 정점으로 흘려보낼 수 있다"라는 의미를 가지게 됩니다. 잔여 간선의 가중치를 가상의 Capacity라고 생각하고 이를 기존 간선들과 함께 표현하면 [A]의 상황은 아래와 같이 표현할 수 있습니다.

기존 [A]의 상황에서 더 이상 찾을 수 없었던 경로가 잔여간선이 추가됨에 따라 A->D->E->B->C->F라는 경로를 찾게 됩니다. 이 경로에 대하여 기존 간선들의 플로우를 2만큼 증가시키고 이 간선들의 잔여 간선을 갱신합니다. 또한 잔여 경로상에 포함된 잔여 간선은 자신의 가중치와 원본 간선의 유량을 2 감소시키면 유량의 흐름은 아래와 같이 변할 수 있습니다.

결국 앞선 [B]상황과 같이 유량이 9인 플로우를 흘리는 경로들을 만들어낼 수 있습니다. 이처럼 Ford-Fulkerson은 탐색을 통해 잔여 간선을 포함한 유량 그래프에서 계속해서 새로운 경로를 찾고 플로우를 흘려보는 과정을 반복함으로써 구현할 수 있습니다.
이 과정을 DFS로 구현해봅시다. Source에서 시작하여 Sink를 만날 때까지 플로우를 추가로 흘릴 수 있는 간선들을 이용하여 사이클이 없도록 탐색합니다. Sink에 도달했을 때, 여태까지 거쳐온 간선들에 흘릴 수 있는 유량들 중 최소값만큼을 해당 경로를 통해 흘린 것으로 갱신하며 차례로 반환합니다. 이때 앞서 설명한 것과 같이 각 간선과 대칭되는 잔여 간선이 동시에 갱신되어야 합니다. 이러한 탐색 과정을 반복하다가 더 이상 갱신할 수 있는 경로를 찾을 수 없을 때, 즉 Source에서 Sink로 가는 경로가 더 이상 존재하지 않을 때 전체 알고리즘을 종료합니다. 아래 예제를 통해 DFS를 수행하는 과정을 알아봅시다.


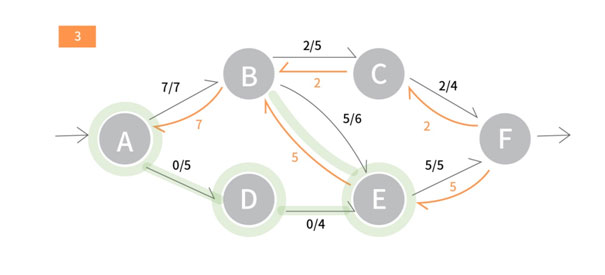
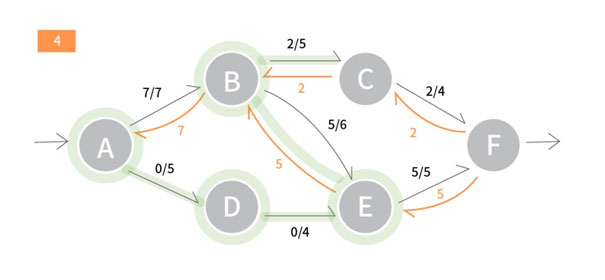


[1] Source A에서 출발합니다. <A, B>간선은 이미 용량이 꽉 찼으므로 사용할 수 없습니다. 따라서 <A, D>를 의 간선을 사용합니다. 이 경로로 추가로 흘릴 수 있는 용량은 (5 - 2)의 값인 3입니다.
[2] D에서 <D, E>간선을 사용합니다. 이 간선으로 추가로 흘릴 수 있는 용량 4가 D로 들어오는 용량 3보다 크므로 이 경로로 추가로 흘릴 수 있는 용량은 여전히 3입니다.
[3] E에서 <E, B>를 사용합니다. <E, B>는 <B, E>에 흐른 5의 플로우에 대한 잔여간선입니다. 우리는 B에서 E로 들어오는 플로우중 3을 다른 경로로 흘려보낼 수 있습니다.
[4] B에서 <B, A> 는 A를 이미 방문했으므로 사용할 필요가 없는 간선입니다. 따라서 <B, C>를 사용합니다. 이는 즉 기존에 <B, E>에서 흐른 용량 중 3을 <B, C>로 우회하여 흘려보내는 것이 됩니다.
[5] C에서< C, B>는 B를 이미 방문했으므로<C, F>를 사용합니다. <C, F>를 통해 추가로 흘려보낼 수 있는 추가용량 2가 C로 들어온 용량 3보다 적기 때문에 이 경로로 추가로 흘릴 수 있는 용량은 2가 됩니다.
[6] F는 Sink입니다. 따라서 우리는 지금까지 사용한 경로를 통해 Source A -> Sink F로 2의 용량을 추가로 흘려보낼 수 있습니다. 이 용량만큼 사용한 경로에 속하는 간선들의 잔여량을 감소시키며 재귀함수를 종료합니다.
이 알고리즘을 위와 같이 DFS로 구현하면 O(F * E)라는 시간복잡도를 가지게 됩니다. F는 그래프에 흐를 수 있는 최대 용량으로, 이러한 시간복잡도를 가지는 이유는 아래와 같은 최악의 경우가 발생할 수 있기 때문입니다.
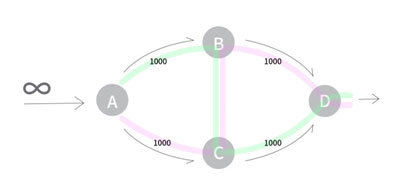
DFS 탐색 순서는 입력 데이터에 따라 그래프마다 달라질 수 있습니다. 우리가 작성한 코드가 위의 그림처럼 간선 <B, C>를 통해 계속 유량을 갱신하게 된다면, 한 번의 탐색에 추가로 흘려보낼 수 있는 용량은 1이 됩니다. 따라서 최대 유량인 2000에 달할 때까지 2000번의 탐색 과정을 반복하게 됩니다. 즉 최대 용량이 커질수록 시간복잡도는 그에 비례해 증가하게 됩니다.
3. Edmond-Karp Algorithm
이러한 문제점을 해결하기 위해 고안된 것이 Edmond-Karp 알고리즘입니다. Edmond-Karp 알고리즘은 앞서 소개한 Ford-Fulkerson 알고리즘과 크게 다르지 않습니다. 다만 Ford-Fulkerson 알고리즘에서 경로를 찾기 위해 DFS로 탐색하던 것을 BFS로 구현합니다.
BFS의 특성상 사용하는 간선의 수가 적은 경로를 우선적으로 발견하게 되며, 결과적으로 앞서 DFS로 인해 발생하는 최악의 경우는 더 이상 생기지 않게 됩니다. Edmond-Karp 알고리즘은 최악의 상황에서도 O(V * E2)에 수행되는 것이 증명되어 있습니다.
이러한 시간복잡도를 비교해보면 유량이 매우 작은 간선으로 이루어진 그래프에서는 DFS로, 반대로 유량이 큰 그래프에서는 BFS로 탐색을 구현하는 것이 보다 성능이 좋습니다.
탐색 과정 역시 앞서 다룬 Ford-Fulkerson과 같습니다. 다만 BFS 탐색 과정을 이용하므로 탐색이 완료되었을 때 목적지부터 출발점까지 사용해온 간선들을 역추적할 수 있도록 이전 노드에 대한 정보를 함께 기록해야 합니다. 아래 몇 가지 과정을 통하여 Edmond-Karp 알고리즘의 동작 과정을 이해해 봅시다.




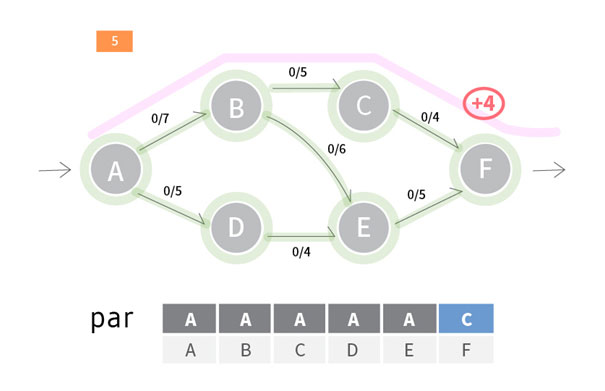


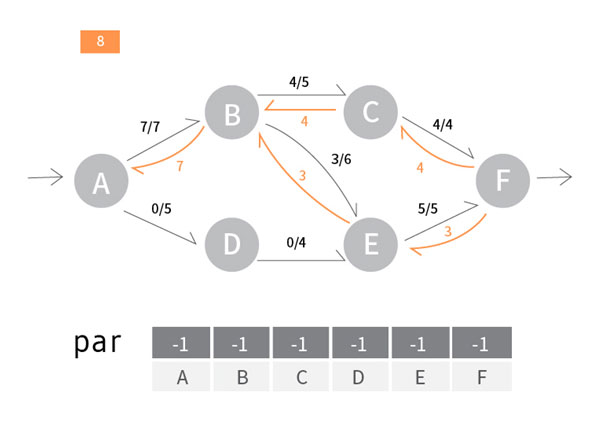


아래는 유량그래프의 정보가 주어졌을 때 최대유량을 구하는 코드입니다.
import java.util.*;
import java.lang.*;
public class Main {
static List<NetworkEdge>[] adj = new ArrayList[101];
static boolean chk[] = new boolean[101];
static int src, sink;
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int v = sc.nextInt();
int e = sc.nextInt();
for (int i = 1; i <= v; i++) {
adj[i] = new ArrayList<NetworkEdge>();
}
src = sc.nextInt();
sink = sc.nextInt();
for (int i = 0; i < e; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int capacity = sc.nextInt();
adj[from].add(new NetworkEdge(to, capacity, 0, adj[to].size()));
adj[to].add(new NetworkEdge(from, 0, 0, adj[from].size() - 1));
}
int ans = 0, added_flow;
while (0 < (added_flow = find_path(src, 101))) {
ans += added_flow;
for (int i = 1; i <= v; i++) {
chk[i] = false;
}
}
System.out.println(ans);
}
public static int find_path(int cur, int addible_flow) {
if (cur == sink) return addible_flow;
chk[cur] = true;
for (int i = 0; i < adj[cur].size(); i++) {
NetworkEdge edge = adj[cur].get(i);
if (chk[edge.to] || edge.capacity - edge.flow == 0) continue;
int added = find_path(edge.to, Math.min(addible_flow, edge.capacity - edge.flow));
if (0 < added) {
edge.flow += added;
adj[edge.to].get(edge.residual_idx).flow -= added;
return added;
}
}
return 0;
}
static class NetworkEdge {
int to, capacity, flow, residual_idx;
NetworkEdge(){}
NetworkEdge(int t, int c, int f, int ridx) {
to = t;
capacity = c;
flow = f;
residual_idx = ridx;
}
}
}